Consensus Outperforms Google Scholar for Academic Search Retrieval

Summary
This evaluation compares Consensus and Google Scholar on the core task of literature review: finding relevant papers. Using 500 real user queries and ~10,000 query–paper pairs, three independent PhD-level researchers blindly evaluated the top 10 results from each system, scoring relevance on a 0–4 scale.
Consensus outperformed Google Scholar across all key search relevance metrics: achieving 7.4% higher average precision and stronger DCG scores, meaning it not only finds more relevant papers but also ranks them with more precision. For researchers, students, and professionals, this means less time sifting and more time learning, proof that smarter academic search is not only possible, and it’s already here.
1. Introduction: Why This Evaluation?
Google Scholar is the gold standard in academic search. While new AI tools (including Consensus) have gained traction in recent years, Google Scholar still dwarfs the rest of us in traffic and usage. Despite its clunky interface, Scholar is still widely considered the most reliable way to find relevant research, quickly.
At Consensus, we’re transparent about our ambition: we want to become the default starting point for literature search. To get there, we need to be better than Google Scholar. This evaluation was designed to answer a simple question: how do we compare on the core task of a literature review—finding relevant papers?
2. Methodology
We compared Consensus (using our Quick search mode) against Google Scholar. Importantly, we did not test our Deep Agentic mode or our Pro Search mode, which can both run iterative, multi-query searches, something a “classic” search engine like Google Scholar doesn’t do.
We hired three independent PhD researchers who have at least a decade of experience evaluating and assessing academic research to score the results. More detail on our methodolgy:
Queries: 500 randomly sampled queries from actual Consensus users (anonymized and scrubbed for all PII) . These ranged from simple keywords, to metadata queries, to natural language questions.
Results: For each query, we pulled the top 10 results from both Consensus and Google Scholar, creating ~10,000 (query, paper) pairs.
Relevance Judging: We relied on the title + abstract for evaluation (due to access restrictions). Each query/paper pair was scored on a 0–4 scale (0 = irrelevant, 4 = perfectly relevant) by all three PhD researchers.
Important note: Scores reflect textual relevance only—not recency, citation count, or journal quality (e.g. a perfectly aligned but obscure 1985 paper could still receive a 4).
Bias control: these labelers have no affiliation with Consensus and were not shown which system the papers came from. They were given a dataset of papers and queries, a set of instructions and nothing more.
3. Results
3.1 Average Precision
Average precision measures the total % of results that were scored as a 3 or 4 (a paper that is overall relevant to the user query). This metric is a good overall measure of how each product does at returning relevant results across user queries.
Consensus outperformed Google Scholar. Consensus achieved an average precision of 88.1%, compared to 81.8% for Google Scholar. Overall, Consensus was 7.4% better (7.3% net points) at returning relevant papers than Google Scholar.

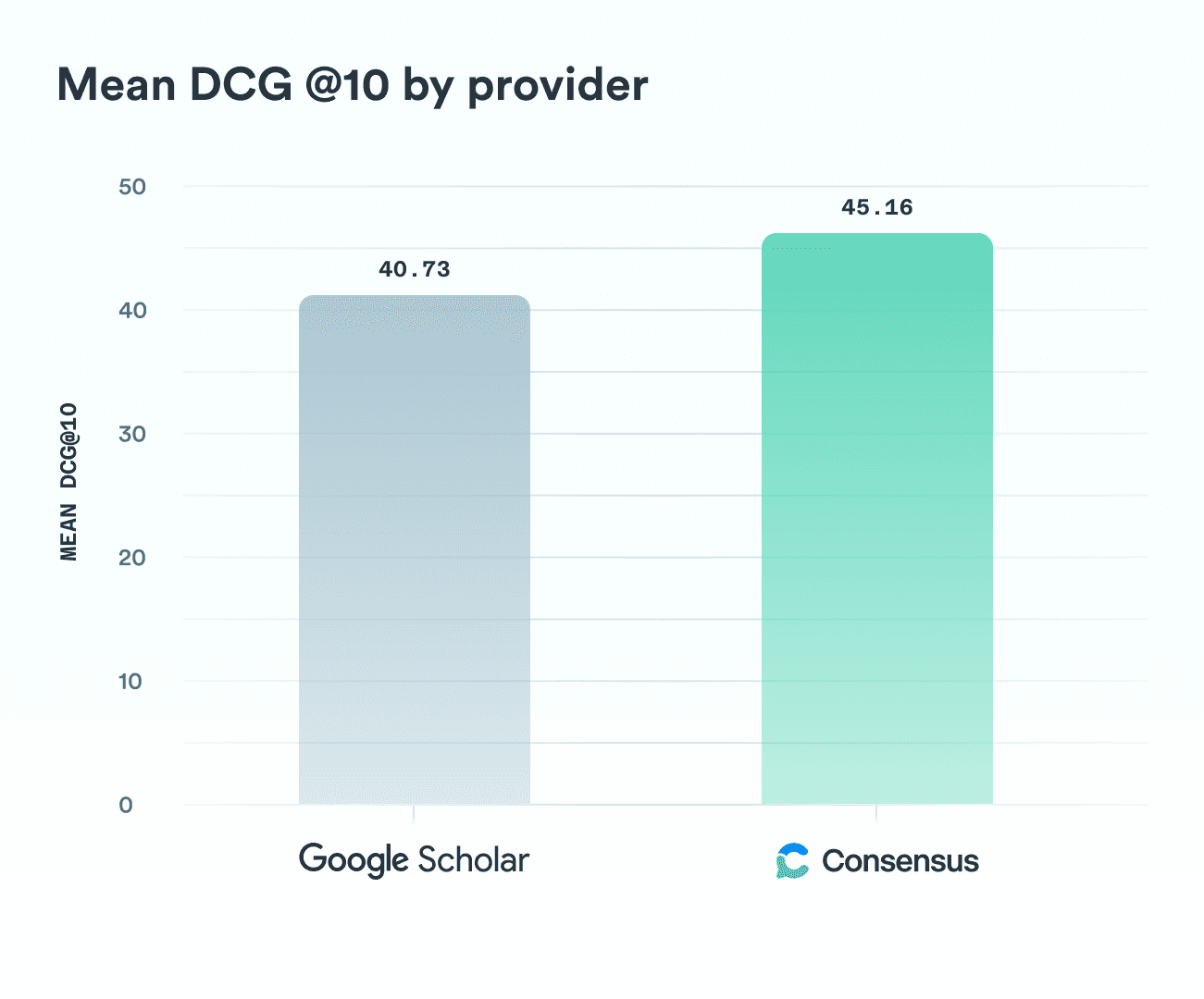
3.2 DCG
Discounted Cumulative Gain (DCG) is a relevance measure of ranking quality that weights higher-ranked results more heavily than lower-ranked ones. In practice, this means that retrieving a relevant paper (score 3 or 4) in the top 5 positions counts more than finding one near the bottom of the list.
Consensus again outperformed Google Scholar. Consensus achieved an average DCG of 45.16, compared to 40.73 for Google Scholar, a 10.3% relative improvement. Overall, Consensus was 10.3% better at placing relevant papers higher in the rankings.
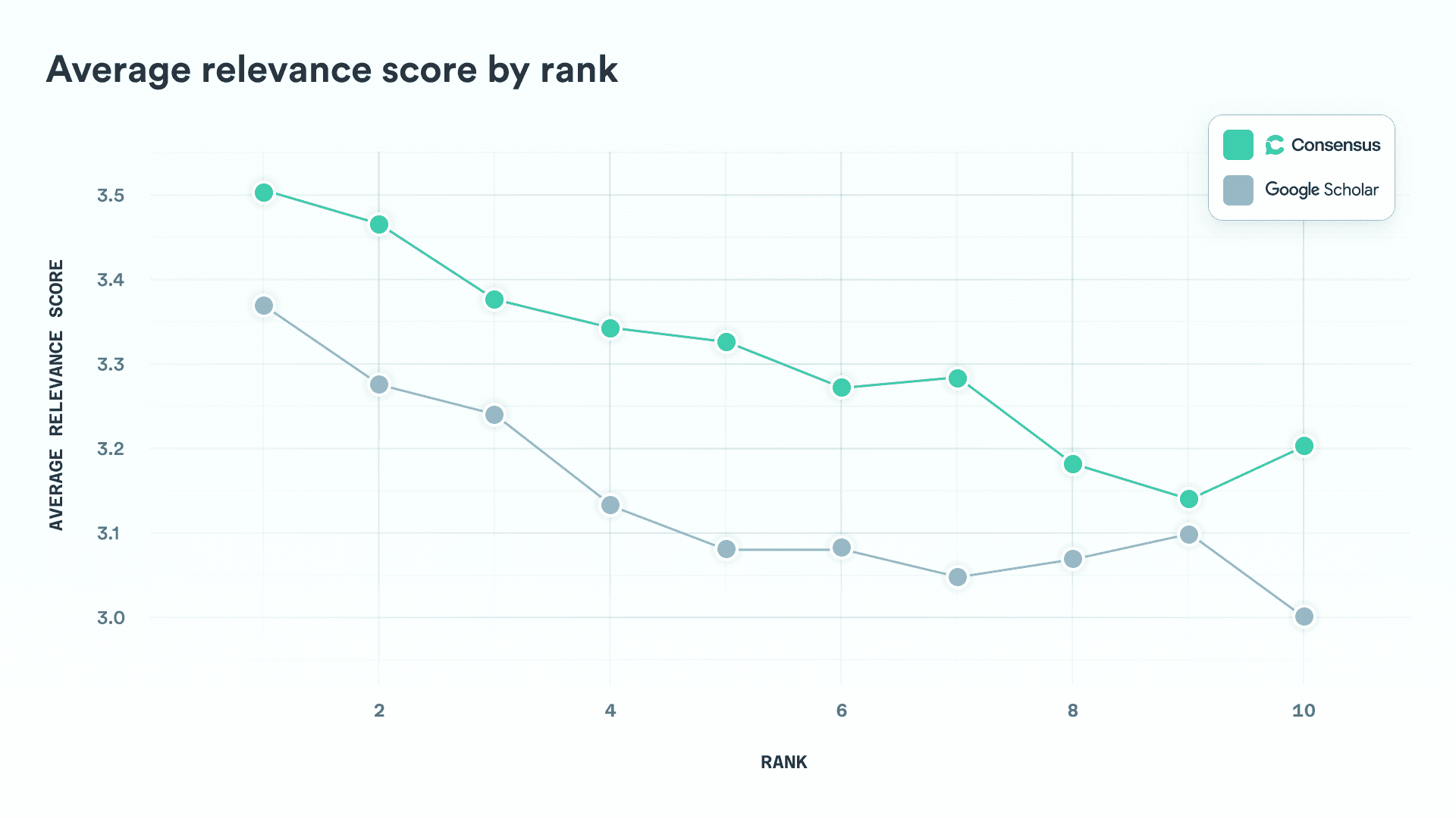
3.3 Average Relevance by Rank
To evaluate performance across the results list, we computed the average relevance score at each rank across all queries.
The pattern is clear and consistent: Consensus delivers higher average relevance at every position in the results, regardless of rank. As expected, relevance declines for both systems as rank increases, which validates the evaluation methodology.
These results highlight the strength of Consensus’s AI-driven ranking systems. While Google Scholar may benefit from unmatched corpus coverage, our findings show that Consensus provides more relevant results throughout the entire ranking, setting a new standard for search quality—not just at the top, but across the board.
4. Conclusion and Discussion
This evaluation shows that Consensus consistently outperforms Google Scholar across the entire results list, with an overall relevance advantage of approximately 7–10%.
These results underscore the impact of Consensus’s AI-driven ranking systems, which deliver stronger relevance at every rank. For researchers, students, and academics, this translates into faster, more efficient discovery of the work that matters most.
More broadly, the findings highlight that search quality is no longer dictated by scale or legacy alone. By advancing ranking intelligence, Consensus demonstrates that more precise, higher-quality scientific discovery is not a future promise of AI, it is here today.
Start searching for free in Consensus!
Consensus searches through 220M+ peer reviewed research papers and provides you the best insights from them. Helping you find better papers, faster.

Sign Up
